Lesson type
Difficulty level

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

This is a tutorial on using the open-source software PRSice to calculate a set of polygenic risk scores (PRS) for a study sample. Users will also learn how to read PRS into R, visualize distributions, and perform basic association analyses.
Difficulty level: Intermediate
Duration: 1:53:34
Speaker: : Dan Felsky

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

Course:
This is an introductory lecture on whole-brain modelling, delving into the various spatial scales of neuroscience, neural population models, and whole-brain modelling. Additionally, the clinical applications of building and testing such models are characterized.
Difficulty level: Intermediate
Duration: 1:24:44
Speaker: : John Griffiths

In this third and final hands-on tutorial from the Research Workflows for Collaborative Neuroscience workshop, you will learn about workflow orchestration using open source tools like DataJoint and Flyte.
Difficulty level: Intermediate
Duration: 22:36
Speaker: : Daniel Xenes

This lecture describes how to build research workflows, including a demonstrate using DataJoint Elements to build data pipelines.
Difficulty level: Intermediate
Duration: 47:00
Speaker: : Dimitri Yatsenko

This lesson describes spike timing-dependent plasticity (STDP), a biological process that adjusts the strength of connections between neurons in the brain, and how one can implement or mimic this process in a computational model. You will also find links for practical exercises at the bottom of this page.
Difficulty level: Intermediate
Duration: 12:50
Speaker: : Dan Goodman

This lesson discusses a gripping neuroscientific question: why have neurons developed the discrete action potential, or spike, as a principle method of communication?
Difficulty level: Intermediate
Duration: 9:34
Speaker: : Dan Goodman

This lesson describes how DataLad allows you to track and mange both your data and analysis code, thereby facilitating reliable, reproducible, and shareable research.
Difficulty level: Intermediate
Duration: 59:34
Speaker: : Yaroslav O. Halchenko

This tutorial covers the fundamentals of collaborating with Git and GitHub.
Difficulty level: Intermediate
Duration: 2:15:50
Speaker: : Elizabeth DuPre

Course:
This lecture and tutorial focuses on measuring human functional brain networks, as well as how to account for inherent variability within those networks.
Difficulty level: Intermediate
Duration: 50:44
Speaker: : Caterina Gratton

Course:
This lesson provides an overview of Jupyter notebooks, Jupyter lab, and Binder, as well as their applications within the field of neuroimaging, particularly when it comes to the writing phase of your research.
Difficulty level: Intermediate
Duration: 50:28
Speaker: : Elizabeth DuPre

This lecture covers how you can make your data public through EBRAINS. This talk focuses on the ethical considerations for sharing data, the requirements that are imposed by various regulations, particularly for sharing human data. The lecture also includes a discussion of how EBRAINS designs its services to deal with the ethical and regulatory aspects of sharing these kinds of data.
Difficulty level: Intermediate
Duration: 16:15
Speaker: : Maaike van Swieten and Jan Bjaalie

This lecture discusses differential privacy and synthetic data in the context of medical data sharing in clinical neurosciences.
Difficulty level: Intermediate
Duration: 20:26
Speaker: : Minos Garofalakis

This talk presents state-of-the-art methods for ensuring data privacy with a particular focus on medical data sharing across multiple organizations.
Difficulty level: Intermediate
Duration: 22:49
Speaker: : Barbara Carminati
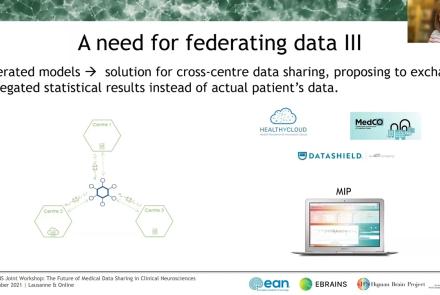
This talks presents ethics requirements of the Medical Informatics Platform, a data sharing platform for medical data using data federation mechanisms. The talk presents how the Medical Informatics Platform (MIP) works and which ethical requirements need to be considered when working with federated data.
Difficulty level: Intermediate
Duration: 16:25
Speaker: : Erika Borcel

This lecture talks about the usage of knowledge graphs in hospitals and related challenges of semantic interoperability.
Difficulty level: Intermediate
Duration: 24:32
Speaker: : Cristophe Gaudet-Blavignac