Lesson type
Difficulty level

This is the first of two workshops on reproducibility in science, during which participants are introduced to concepts of FAIR and open science. After discussing the definition of and need for FAIR science, participants are walked through tutorials on installing and using Github and Docker, the powerful, open-source tools for versioning and publishing code and software, respectively.
Difficulty level: Intermediate
Duration: 1:20:58
Speaker: : Erin Dickie and Sejal Patel

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

This is a tutorial on using the open-source software PRSice to calculate a set of polygenic risk scores (PRS) for a study sample. Users will also learn how to read PRS into R, visualize distributions, and perform basic association analyses.
Difficulty level: Intermediate
Duration: 1:53:34
Speaker: : Dan Felsky

This lecture goes into detailed description of how to process workflows in the virtual research environment (VRE), including approaches for standardization, metadata, containerization, and constructing and maintaining scientific pipelines.
Difficulty level: Intermediate
Duration: 1:03:55
Speaker: : Patrik Bey

In this third and final hands-on tutorial from the Research Workflows for Collaborative Neuroscience workshop, you will learn about workflow orchestration using open source tools like DataJoint and Flyte.
Difficulty level: Intermediate
Duration: 22:36
Speaker: : Daniel Xenes

This lecture describes how to build research workflows, including a demonstrate using DataJoint Elements to build data pipelines.
Difficulty level: Intermediate
Duration: 47:00
Speaker: : Dimitri Yatsenko

This lesson delves into the human nervous system and the immense cellular, connectomic, and functional sophistication therein.
Difficulty level: Intermediate
Duration: 8:41
Speaker: : Marcus Ghosh

This lecture provides an introduction to the Brain Imaging Data Structure (BIDS), a standard for organizing human neuroimaging datasets.
Difficulty level: Intermediate
Duration: 56:49
Speaker: : Chris Gorgolewski

This tutorial covers the fundamentals of collaborating with Git and GitHub.
Difficulty level: Intermediate
Duration: 2:15:50
Speaker: : Elizabeth DuPre

Course:
This lesson provides an overview of Jupyter notebooks, Jupyter lab, and Binder, as well as their applications within the field of neuroimaging, particularly when it comes to the writing phase of your research.
Difficulty level: Intermediate
Duration: 50:28
Speaker: : Elizabeth DuPre

This lecture gives an overview of how to prepare and preprocess neuroimaging (EEG/MEG) data for use in TVB.
Difficulty level: Intermediate
Duration: 1:40:52
Speaker: : Paul Triebkorn

This is the Introductory Module to the Deep Learning Course at CDS, a course that covered the latest techniques in deep learning and representation learning, focusing on supervised and unsupervised deep learning, embedding methods, metric learning, convolutional and recurrent nets, with applications to computer vision, natural language understanding, and speech recognition.
Difficulty level: Intermediate
Duration: 50:17
Speaker: : Yann LeCun and Alfredo Canziani

This module covers the concepts of gradient descent and the backpropagation algorithm and is a part of the Deep Learning Course at NYU's Center for Data Science.
Difficulty level: Intermediate
Duration: 1:51:03
Speaker: : Yann LeCun

This lecture covers the concept of parameter sharing: recurrent and convolutional nets and is a part of the Deep Learning Course at NYU's Center for Data Science.
Difficulty level: Intermediate
Duration: 1:59:47
Speaker: : Yann LeCun and Alfredo Canziani

This lecture covers the concept of convolutional nets in practice and is a part of the Deep Learning Course at NYU's Center for Data Science.
Difficulty level: Intermediate
Duration: 51:40
Speaker: : Yann LeCun

This lecture discusses the concept of natural signals properties and the convolutional nets in practice and is a part of the Deep Learning Course at NYU's Center for Data Science.
Difficulty level: Intermediate
Duration: 1:09:12
Speaker: : Alfredo Canziani

This lecture covers the concept of recurrent neural networks: vanilla and gated (LSTM) and is a part of the Deep Learning Course at NYU's Center for Data Science.
Difficulty level: Intermediate
Duration: 1:05:36
Speaker: : Alfredo Canziani
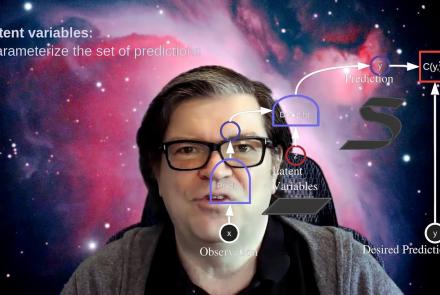
This lecture is a foundationational lecture for the concept of energy-based models with a particular focus on the joint embedding method and latent variable energy-based models (LV-EBMs) and is a part of the Deep Learning Course at NYU's Center for Data Science.
Difficulty level: Intermediate
Duration: 1:51:30
Speaker: : Yann LeCun

This lecture covers the concept of inference in latent variable energy based models (LV-EBMs) and is a part of the Deep Learning Course at NYU's Center for Data Science.
Difficulty level: Intermediate
Duration: 1:01:04
Speaker: : Alfredo Canziani

This lecture is a foundationational lecture for the concept of energy-based models with a particular focus on the joint embedding method and latent variable energy based models (LV-EBMs) and is a part of the Deep Learning Course at NYU's Center for Data Science.
Difficulty level: Intermediate
Duration: 1:48:53
Speaker: : Yann LeCun