Lesson type
Difficulty level

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This lesson describes a definitional framework for fairness and health equity in the age of the algorithm. While acknowledging the impressive capability of machine learning to positively affect health equity, this talk outlines potential (and actual) pitfalls which come with such powerful tools, ultimately making the case for collaborative, interdisciplinary, and transparent science as a way to operationalize fairness in health equity.
Difficulty level: Beginner
Duration: 1:06:35
Speaker: : Laura Sikstrom

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lecture discusses what defines an integrative approach regarding research and methods, including various study designs and models which are appropriate choices when attempting to bridge data domains; a necessity when whole-person modelling.
Difficulty level: Beginner
Duration: 1:28:14
Speaker: : Dan Felsky

This lecture covers a lot of post-war developments in the science of the mind, focusing first on the cognitive revolution, and concluding with living machines.
Difficulty level: Beginner
Duration: 2:24:35
Speaker: : Paul F.M.J. Verschure

This talk enumerates the challenges regarding data accessibility and reusability inherent in the current scientific publication system, and discusses novel approaches to these challenges, such as the EBRAINS Live Papers platform.
Difficulty level: Beginner
Duration: 18:08
Speaker: : Andrew Davison

This brief talk goes into work being done at The Alan Turing Institute to solve real-world challenges and democratize computer vision methods to support interdisciplinary and international researchers.
Difficulty level: Beginner
Duration: 7:10
Speaker: : Alden Connor & Beatriz Costa Gomes

This lesson is the first part of a three-part series on the development of neuroinformatic infrastructure to ensure compliance with European data privacy standards and laws.
Difficulty level: Beginner
Duration: 1:10:05
Speaker: : Michael Schirner

This is the second of three lectures around current challenges and opportunities facing neuroinformatic infrastructure for handling sensitive data.
Difficulty level: Beginner
Duration: 48:26
Speaker: : Michael Schirner

This lesson contains the first part of the lecture Data Science and Reproducibility. You will learn about the development of data science and what the term currently encompasses, as well as how neuroscience and data science intersect.
Difficulty level: Beginner
Duration: 32:18
Speaker: : Ariel Rokem

This lesson aims to define computational neuroscience in general terms, while providing specific examples of highly successful computational neuroscience projects.
Difficulty level: Beginner
Duration: 59:21
Speaker: : Alla Borisyuk

This lecture gives a tour of what neuroethics is and how it applies to neuroscience and neurotechnology, while also addressing justice concerns within both fields.
Difficulty level: Beginner
Duration: 58:45
Speaker: : Tim Brown

Course:
This lecture gives an introduction to simulation, models, and the neural simulation tool NEST.
Difficulty level: Beginner
Duration: 1:48:18
Speaker: : Marc-Oliver Gewaltig

Course:
This lecture covers an Introduction to neuron anatomy and signaling, and different types of models, including the Hodgkin-Huxley model.
Difficulty level: Beginner
Duration: 1:23:01
Speaker: : Gaute Einevoll
This lecture covers an Introduction to neuron anatomy and signaling, and different types of models, including the Hodgkin-Huxley model.
Difficulty level: Beginner
Duration: 1:23:01
Speaker: : Gaute Einevoll

This lesson discuses forms of neural plasticity on many levels, including short-term, long-term, metaplasticity, and structural plasticity. During the lesson you will also be presented with examples related to the modelling of biochemical networks.
Difficulty level: Beginner
Duration: 1:11:29
Speaker: : Upi Bhalla

This lesson provides an introduction to modelling of chemical computation in the brain.
Difficulty level: Beginner
Duration: 1:00:11
Speaker: : Upi Bhalla

This lesson is part 1 of 2 of a tutorial on statistical models for neural data.
Difficulty level: Beginner
Duration: 1:45:48
Speaker: : Jonathan Pillow
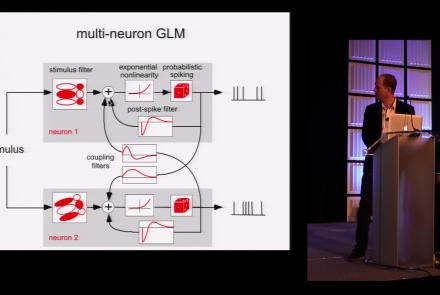
This lesson is part 2 of 2 of a tutorial on statistical models for neural data.
Difficulty level: Beginner
Duration: 1:50:31
Speaker: : Jonathan Pillow
Course:
This lesson gives an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan