Lesson type
Difficulty level

Course:
This lesson provides an overview of the database of Genotypes and Phenotypes (dbGaP), which was developed to archive and distribute the data and results from studies that have investigated the interaction of genotype and phenotype in humans.
Difficulty level: Beginner
Duration: 48:22
Speaker: : Michael Feolo

Course:
This lesson introduces the EEGLAB toolbox, as well as motivations for its use.
Difficulty level: Beginner
Duration: 15:32
Speaker: : Arnaud Delorme
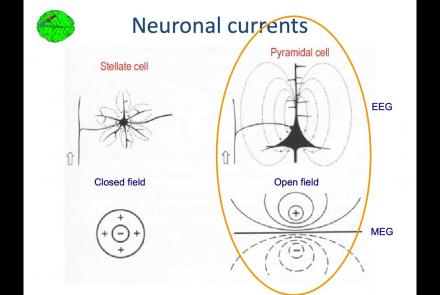
Course:
In this lesson, you will learn about the biological activity which generates and is measured by the EEG signal.
Difficulty level: Beginner
Duration: 6:53
Speaker: : Arnaud Delorme

Course:
This lesson goes over the characteristics of EEG signals when analyzed in source space (as opposed to sensor space).
Difficulty level: Beginner
Duration: 10:56
Speaker: : Arnaud Delorme

Course:
This lesson describes the development of EEGLAB as well as to what extent it is used by the research community.
Difficulty level: Beginner
Duration: 6:06
Speaker: : Arnaud Delorme

Course:
This lesson provides instruction as to how to build a processing pipeline in EEGLAB for a single participant.
Difficulty level: Beginner
Duration: 9:20
Speaker: :

Course:
Whereas the previous lesson of this course outlined how to build a processing pipeline for a single participant, this lesson discusses analysis pipelines for multiple participants simultaneously.
Difficulty level: Beginner
Duration: 10:55
Speaker: : Arnaud Delorme

Course:
In addition to outlining the motivations behind preprocessing EEG data in general, this lesson covers the first step in preprocessing data with EEGLAB, importing raw data.
Difficulty level: Beginner
Duration: 8:30
Speaker: : Arnaud Delorme

Course:
Continuing along the EEGLAB preprocessing pipeline, this tutorial walks users through how to import data events as well as EEG channel locations.
Difficulty level: Beginner
Duration: 11:53
Speaker: : Arnaud Delorme

Course:
This tutorial instructs users how to visually inspect partially pre-processed neuroimaging data in EEGLAB, specifically how to use the data browser to investigate specific channels, epochs, or events for removable artifacts, biological (e.g., eye blinks, muscle movements, heartbeat) or otherwise (e.g., corrupt channel, line noise).
Difficulty level: Beginner
Duration: 5:08
Speaker: : Arnaud Delorme

Course:
This tutorial provides instruction on how to use EEGLAB to further preprocess EEG datasets by identifying and discarding bad channels which, if left unaddressed, can corrupt and confound subsequent analysis steps.
Difficulty level: Beginner
Duration: 13:01
Speaker: : Arnaud Delorme

Course:
Users following this tutorial will learn how to identify and discard bad EEG data segments using the MATLAB toolbox EEGLAB.
Difficulty level: Beginner
Duration: 11:25
Speaker: : Arnaud Delorme

In this workshop talk, you will receive a tour of the Code Ocean ScienceOps Platform, a centralized cloud workspace for all teams.
Difficulty level: Beginner
Duration: 10:24
Speaker: : Frank Zappulla

This talk describes approaches to maintaining integrated workflows and data management schema, taking advantage of the many open source, collaborative platforms already existing.
Difficulty level: Beginner
Duration: 15:15
Speaker: : Erik C. Johnson

This lesson provides an introduction to the DataLad, a free and open source distributed data management system that keeps track of your data, creates structure, ensures reproducibility, supports collaboration, and integrates with widely used data infrastructure.
Difficulty level: Beginner
Duration: 22:56
Speaker: : Michał Szczepanik

This lesson introduces several open science tools like Docker and Apptainer which can be used to develop portable and reproducible software environments.
Difficulty level: Beginner
Duration: 17:22
Speaker: : Joanes Grandjean

This lecture provides a detailed description of how to incorporate HED annotation into your neuroimaging data pipeline.
Difficulty level: Beginner
Duration: 33:36
Speaker: : Dung Truong

Course:
This video will teach you the basics of navigating the Open Science Framework and creating your first projects.
Difficulty level: Beginner
Duration: 2:11
Speaker: :

Course:
This webinar walks you through the basics of creating an OSF project, structuring it to fit your research needs, adding collaborators, and tying your favorite online tools into your project structure.
Difficulty level: Beginner
Duration: 55:02
Speaker: : Ian Sullivan
Course:
This webinar will introduce how to use the Open Science Framework (OSF) in a classroom setting.
Difficulty level: Beginner
Duration: 32:01
Speaker: : April Clyburne-Sherin