Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson provides an overview of how to conceptualize, design, implement, and maintain neuroscientific pipelines in via the cloud-based computational reproducibility platform Code Ocean.
Difficulty level: Beginner
Duration: 17:01
Speaker: : David Feng

This lesson provides an overview of how to construct computational pipelines for neurophysiological data using DataJoint.
Difficulty level: Beginner
Duration: 17:37
Speaker: : Dimitri Yatsenko

This hands-on tutorial walks you through DataJoint platform, highlighting features and schema which can be used to build robost neuroscientific pipelines.
Difficulty level: Beginner
Duration: 26:06
Speaker: : Milagros Marin

This lesson provides an introduction to the DataLad, a free and open source distributed data management system that keeps track of your data, creates structure, ensures reproducibility, supports collaboration, and integrates with widely used data infrastructure.
Difficulty level: Beginner
Duration: 22:56
Speaker: : Michał Szczepanik

This lesson introduces several open science tools like Docker and Apptainer which can be used to develop portable and reproducible software environments.
Difficulty level: Beginner
Duration: 17:22
Speaker: : Joanes Grandjean

This lecture provides a detailed description of how to incorporate HED annotation into your neuroimaging data pipeline.
Difficulty level: Beginner
Duration: 33:36
Speaker: : Dung Truong

This lecture covers a wide range of aspects regarding neuroinformatics and data governance, describing both their historical developments and current trajectories. Particular tools, platforms, and standards to make your research more FAIR are also discussed.
Difficulty level: Beginner
Duration: 54:58
Speaker: : Franco Pestilli

Course:
In this tutorial, you will learn the basic features of uploading and versioning your data within OpenNeuro.org.
Difficulty level: Beginner
Duration: 5:36
Speaker: : OpenNeuro

Course:
This tutorial shows how to share your data in OpenNeuro.org.
Difficulty level: Beginner
Duration: 1:22
Speaker: : OpenNeuro

Course:
Following the previous two tutorials on uploading and sharing data with OpenNeuro.org, this tutorial briefly covers how to run various analyses on your datasets.
Difficulty level: Beginner
Duration: 2:26
Speaker: : OpenNeuro

This talk highlights a set of platform technologies, software, and data collections that close and shorten the feedback cycle in research.
Difficulty level: Beginner
Duration: 57:52
Speaker: : Satrajit Ghosh

Course:
This talk covers the Neuroimaging Informatics Tools and Resources Clearinghouse (NITRC), a free one-stop-shop collaboratory for science researchers that need resources such as neuroimaging analysis software, publicly available data sets, or computing power.
Difficulty level: Beginner
Duration: 1:00:10
Speaker: : David Kennedy

Course:
This lesson provides an overview of the database of Genotypes and Phenotypes (dbGaP), which was developed to archive and distribute the data and results from studies that have investigated the interaction of genotype and phenotype in humans.
Difficulty level: Beginner
Duration: 48:22
Speaker: : Michael Feolo

Course:
This lesson introduces the EEGLAB toolbox, as well as motivations for its use.
Difficulty level: Beginner
Duration: 15:32
Speaker: : Arnaud Delorme
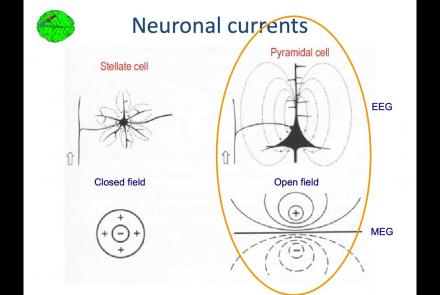
Course:
In this lesson, you will learn about the biological activity which generates and is measured by the EEG signal.
Difficulty level: Beginner
Duration: 6:53
Speaker: : Arnaud Delorme

Course:
This lesson goes over the characteristics of EEG signals when analyzed in source space (as opposed to sensor space).
Difficulty level: Beginner
Duration: 10:56
Speaker: : Arnaud Delorme

Course:
This lesson describes the development of EEGLAB as well as to what extent it is used by the research community.
Difficulty level: Beginner
Duration: 6:06
Speaker: : Arnaud Delorme

Course:
This lesson provides instruction as to how to build a processing pipeline in EEGLAB for a single participant.
Difficulty level: Beginner
Duration: 9:20
Speaker: :

Course:
Whereas the previous lesson of this course outlined how to build a processing pipeline for a single participant, this lesson discusses analysis pipelines for multiple participants simultaneously.
Difficulty level: Beginner
Duration: 10:55
Speaker: : Arnaud Delorme