Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

Course:
In this lesson, while learning about the need for increased large-scale collaborative science that is transparent in nature, users also are given a tutorial on using Synapse for facilitating reusable and reproducible research.
Difficulty level: Beginner
Duration: 1:15:12
Speaker: : Abhi Pratap

In this workshop talk, you will receive a tour of the Code Ocean ScienceOps Platform, a centralized cloud workspace for all teams.
Difficulty level: Beginner
Duration: 10:24
Speaker: : Frank Zappulla

This talk describes approaches to maintaining integrated workflows and data management schema, taking advantage of the many open source, collaborative platforms already existing.
Difficulty level: Beginner
Duration: 15:15
Speaker: : Erik C. Johnson

Course:
KnowledgeSpace is a community-based encyclopedia that links brain research concepts to data, models, and literature. It provides users with access to anatomy, gene expression, models, morphology, and physiology data from over 15 different neuroscience data/model repositories, such as Allen Institute for Brain Science and the Human Brain Project.
Difficulty level: Beginner
Duration: 0:58
Speaker: : Tom Gillespie

Course:
Longitudinal Online Research and Imaging System (LORIS) is a web-based data and project management software for neuroimaging research studies. It is an open source framework for storing and processing behavioural, clinical, neuroimaging and genetic data. LORIS also makes it easy to manage large datasets acquired over time in a longitudinal study, or at different locations in a large multi-site study.
Difficulty level: Beginner
Duration: 0:35
Speaker: : Samir Das

This talk highlights a set of platform technologies, software, and data collections that close and shorten the feedback cycle in research.
Difficulty level: Beginner
Duration: 57:52
Speaker: : Satrajit Ghosh

Course:
This lesson outlines NeuroMorpho.org, a centrally curated inventory of digitally reconstructed neurons, which contrains contributions from dozens of laboratories worldwide and is continuously updated as new morphological reconstructions are collected, published, and shared.
Difficulty level: Beginner
Duration: 1:03:29
Speaker: : Ruben Armananzas

Course:
This lesson describes the Neuroscience Gateway , which facilitates access and use of National Science Foundation High Performance Computing resources by neuroscientists.
Difficulty level: Beginner
Duration: 39:27
Speaker: : Subha Sivagnanam

Course:
This lesson introduces the EEGLAB toolbox, as well as motivations for its use.
Difficulty level: Beginner
Duration: 15:32
Speaker: : Arnaud Delorme
Course:
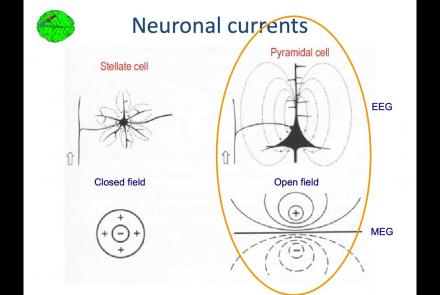
In this lesson, you will learn about the biological activity which generates and is measured by the EEG signal.
Difficulty level: Beginner
Duration: 6:53
Speaker: : Arnaud Delorme

Course:
This lesson goes over the characteristics of EEG signals when analyzed in source space (as opposed to sensor space).
Difficulty level: Beginner
Duration: 10:56
Speaker: : Arnaud Delorme

Course:
This lesson describes the development of EEGLAB as well as to what extent it is used by the research community.
Difficulty level: Beginner
Duration: 6:06
Speaker: : Arnaud Delorme

Course:
This lesson provides instruction as to how to build a processing pipeline in EEGLAB for a single participant.
Difficulty level: Beginner
Duration: 9:20
Speaker: :

Course:
Whereas the previous lesson of this course outlined how to build a processing pipeline for a single participant, this lesson discusses analysis pipelines for multiple participants simultaneously.
Difficulty level: Beginner
Duration: 10:55
Speaker: : Arnaud Delorme

Course:
In addition to outlining the motivations behind preprocessing EEG data in general, this lesson covers the first step in preprocessing data with EEGLAB, importing raw data.
Difficulty level: Beginner
Duration: 8:30
Speaker: : Arnaud Delorme

Course:
Continuing along the EEGLAB preprocessing pipeline, this tutorial walks users through how to import data events as well as EEG channel locations.
Difficulty level: Beginner
Duration: 11:53
Speaker: : Arnaud Delorme

Course:
This tutorial instructs users how to visually inspect partially pre-processed neuroimaging data in EEGLAB, specifically how to use the data browser to investigate specific channels, epochs, or events for removable artifacts, biological (e.g., eye blinks, muscle movements, heartbeat) or otherwise (e.g., corrupt channel, line noise).
Difficulty level: Beginner
Duration: 5:08
Speaker: : Arnaud Delorme

Course:
This tutorial provides instruction on how to use EEGLAB to further preprocess EEG datasets by identifying and discarding bad channels which, if left unaddressed, can corrupt and confound subsequent analysis steps.
Difficulty level: Beginner
Duration: 13:01
Speaker: : Arnaud Delorme

Course:
Users following this tutorial will learn how to identify and discard bad EEG data segments using the MATLAB toolbox EEGLAB.
Difficulty level: Beginner
Duration: 11:25
Speaker: : Arnaud Delorme