Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

In this workshop talk, you will receive a tour of the Code Ocean ScienceOps Platform, a centralized cloud workspace for all teams.
Difficulty level: Beginner
Duration: 10:24
Speaker: : Frank Zappulla

This talk describes approaches to maintaining integrated workflows and data management schema, taking advantage of the many open source, collaborative platforms already existing.
Difficulty level: Beginner
Duration: 15:15
Speaker: : Erik C. Johnson

This lecture covers a wide range of aspects regarding neuroinformatics and data governance, describing both their historical developments and current trajectories. Particular tools, platforms, and standards to make your research more FAIR are also discussed.
Difficulty level: Beginner
Duration: 54:58
Speaker: : Franco Pestilli

Course:
In this tutorial, you will learn the basic features of uploading and versioning your data within OpenNeuro.org.
Difficulty level: Beginner
Duration: 5:36
Speaker: : OpenNeuro

Course:
This tutorial shows how to share your data in OpenNeuro.org.
Difficulty level: Beginner
Duration: 1:22
Speaker: : OpenNeuro

Course:
Following the previous two tutorials on uploading and sharing data with OpenNeuro.org, this tutorial briefly covers how to run various analyses on your datasets.
Difficulty level: Beginner
Duration: 2:26
Speaker: : OpenNeuro

Manipulate the default connectome provided with TVB to see how structural lesions effect brain dynamics. In this hands-on session you will insert lesions into the connectome within the TVB graphical user interface (GUI). Afterwards, the modified connectome will be used for simulations and the resulting activity will be analysed using functional connectivity.
Difficulty level: Beginner
Duration: 31:22
Speaker: : Paul Triebkorn

Course:
In this lesson you will learn how to simulate seizure events and epilepsy in The Virtual Brain. We will look at the paper On the Nature of Seizure Dynamics, which describes a new local model called the Epileptor, and apply this same model in The Virtual Brain. This is part 1 of 2 in a series explaining how to use the Epileptor. In this part, we focus on setting up the parameters.
Difficulty level: Beginner
Duration: 4:44
Speaker: : Paul Triebkorn

Course:
KnowledgeSpace is a community-based encyclopedia that links brain research concepts to data, models, and literature. It provides users with access to anatomy, gene expression, models, morphology, and physiology data from over 15 different neuroscience data/model repositories, such as Allen Institute for Brain Science and the Human Brain Project.
Difficulty level: Beginner
Duration: 0:58
Speaker: : Tom Gillespie

This talk highlights a set of platform technologies, software, and data collections that close and shorten the feedback cycle in research.
Difficulty level: Beginner
Duration: 57:52
Speaker: : Satrajit Ghosh

Course:
This lesson outlines NeuroMorpho.org, a centrally curated inventory of digitally reconstructed neurons, which contrains contributions from dozens of laboratories worldwide and is continuously updated as new morphological reconstructions are collected, published, and shared.
Difficulty level: Beginner
Duration: 1:03:29
Speaker: : Ruben Armananzas

Course:
This lesson describes the Neuroscience Gateway , which facilitates access and use of National Science Foundation High Performance Computing resources by neuroscientists.
Difficulty level: Beginner
Duration: 39:27
Speaker: : Subha Sivagnanam

Course:
This lesson provides an overview of the database of Genotypes and Phenotypes (dbGaP), which was developed to archive and distribute the data and results from studies that have investigated the interaction of genotype and phenotype in humans.
Difficulty level: Beginner
Duration: 48:22
Speaker: : Michael Feolo

Course:
This lesson introduces the EEGLAB toolbox, as well as motivations for its use.
Difficulty level: Beginner
Duration: 15:32
Speaker: : Arnaud Delorme
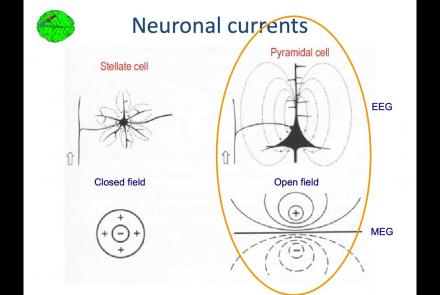
Course:
In this lesson, you will learn about the biological activity which generates and is measured by the EEG signal.
Difficulty level: Beginner
Duration: 6:53
Speaker: : Arnaud Delorme

Course:
This lesson goes over the characteristics of EEG signals when analyzed in source space (as opposed to sensor space).
Difficulty level: Beginner
Duration: 10:56
Speaker: : Arnaud Delorme

Course:
This lesson describes the development of EEGLAB as well as to what extent it is used by the research community.
Difficulty level: Beginner
Duration: 6:06
Speaker: : Arnaud Delorme

Course:
This lesson provides instruction as to how to build a processing pipeline in EEGLAB for a single participant.
Difficulty level: Beginner
Duration: 9:20
Speaker: :

Course:
Whereas the previous lesson of this course outlined how to build a processing pipeline for a single participant, this lesson discusses analysis pipelines for multiple participants simultaneously.
Difficulty level: Beginner
Duration: 10:55
Speaker: : Arnaud Delorme