Lesson type
Difficulty level

Course:
The state of the field regarding the diagnosis and treatment of major depressive disorder (MDD) is discussed. Current challenges and opportunities facing the research and clinical communities are outlined, including appropriate quantitative and qualitative analyses of the heterogeneity of biological, social, and psychiatric factors which may contribute to MDD.
Difficulty level: Beginner
Duration: 1:29:28
Speaker: : Brett Jones, Victor Tang

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This lesson describes a definitional framework for fairness and health equity in the age of the algorithm. While acknowledging the impressive capability of machine learning to positively affect health equity, this talk outlines potential (and actual) pitfalls which come with such powerful tools, ultimately making the case for collaborative, interdisciplinary, and transparent science as a way to operationalize fairness in health equity.
Difficulty level: Beginner
Duration: 1:06:35
Speaker: : Laura Sikstrom

Course:
This lesson delves into the opportunities and challenges of telepsychiatry. While novel digital approaches to clinical research and care have the potential to improve and accelerate patient outcomes, researchers and care providers must consider new population factors, such as digital disparity.
Difficulty level: Beginner
Duration: 1:20:28
Speaker: : Abhi Pratap

In this lesson, you will learn about the current challenges facing the integration of machine learning and neuroscience.
Difficulty level: Beginner
Duration: 5:42
Speaker: : Dan Goodman
This lecture focuses on how the immune system can target and attack the nervous system to produce autoimmune responses that may result in diseases such as multiple sclerosis, neuromyelitis, and lupus cerebritis manifested by motor, sensory, and cognitive impairments. Despite the fact that the brain is an immune-privileged site, autoreactive lymphocytes producing proinflammatory cytokines can cause active brain inflammation, leading to myelin and axonal loss.
Difficulty level: Beginner
Duration: 37:36
Speaker: : Anat Achiron
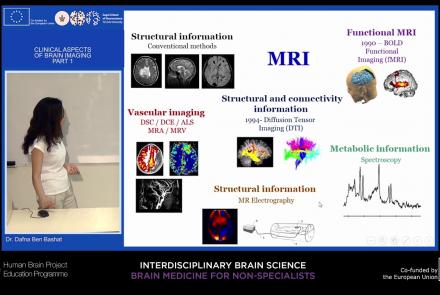
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat
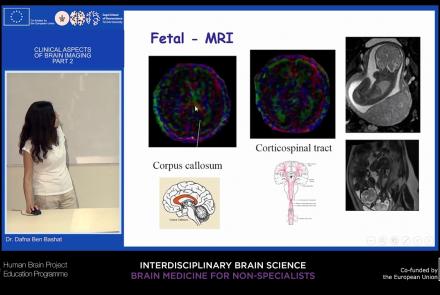
This lecture picks up from the previous lesson, providing an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 41:00
Speaker: : Dafna Ben Bashat

This lesson discusses both state-of-the-art detection and prevention schema in working with neurodegenerative diseases.
Difficulty level: Beginner
Duration: 1:02:29
Speaker: : Nir Giladi

This lesson provides a basic introduction to clinical presentation of schizophrenia, its etiology, and current treatment options.
Difficulty level: Beginner
Duration: 51:49
Speaker: : Wolfgang Fleischhacker

This lecture focuses on the rationale for employing neuroimaging methods for movement disorders.
Difficulty level: Beginner
Duration: 1:04:04
Speaker: : Bogdan Draganski
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke

This lecture covers how to make modeling workflows FAIR by working through a practical example, dissecting the steps within the workflow, and detailing the tools and resources used at each step.
Difficulty level: Beginner
Duration: 15:14
Speaker: : Salvador Dura-Bernal

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani