Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26
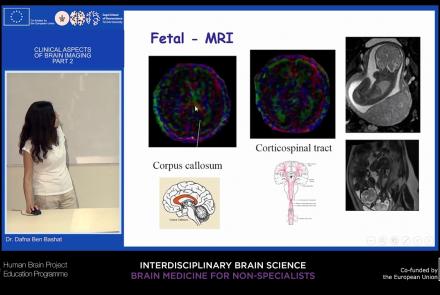
This lecture picks up from the previous lesson, providing an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 41:00
Speaker: : Dafna Ben Bashat

This lesson provides a basic introduction to clinical presentation of schizophrenia, its etiology, and current treatment options.
Difficulty level: Beginner
Duration: 51:49
Speaker: : Wolfgang Fleischhacker

In this lesson, you will learn about how genetics can contribute to our understanding of psychiatric phenotypes.
Difficulty level: Beginner
Duration: 55:15
Speaker: : Sven Cichon

This lecture focuses on the rationale for employing neuroimaging methods for movement disorders.
Difficulty level: Beginner
Duration: 1:04:04
Speaker: : Bogdan Draganski

This lecture provides an overview of some of the essential concepts in neuropharmacology (e.g. receptor binding, agonism, antagonism), an introduction to pharmacodynamics and pharmacokinetics, and an overview of the drug discovery process relative to diseases of the central nervous system.
Difficulty level: Beginner
Duration: 45:47
Speaker: : Sandra Santos-Sierra
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

In this lesson, you will hear about the current challenges regarding data management, as well as policies and resources aimed to address them.
Difficulty level: Beginner
Duration: 18:13
Speaker: : Mojib Javadi

This lecture covers how to make modeling workflows FAIR by working through a practical example, dissecting the steps within the workflow, and detailing the tools and resources used at each step.
Difficulty level: Beginner
Duration: 15:14
Speaker: : Salvador Dura-Bernal

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz

This lecture contains an overview of electrophysiology data reuse within the EBRAINS ecosystem.
Difficulty level: Beginner
Duration: 15:57
Speaker: : Andrew Davison
This lecture contains an overview of the Distributed Archives for Neurophysiology Data Integration (DANDI) archive, its ties to FAIR and open-source, integrations with other programs, and upcoming features.
Difficulty level: Beginner
Duration: 13:34
Speaker: : Yaroslav O. Halchenko
This lecture discusses how to standardize electrophysiology data organization to move towards being more FAIR.
Difficulty level: Beginner
Duration: 15:51
Speaker: : Sylvain Takerkart

Course:
This lesson gives an introduction to high-performance computing with the Compute Canada network, first providing an overview of use cases for HPC and then a hands-on tutorial. Though some examples might seem specific to the Calcul Québec, all computing clusters in the Compute Canada network share the same software modules and environments.
Difficulty level: Beginner
Duration: 02:49:34
Speaker: : Félix-Antoine Fortin