Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

Course:
In this lesson, while learning about the need for increased large-scale collaborative science that is transparent in nature, users also are given a tutorial on using Synapse for facilitating reusable and reproducible research.
Difficulty level: Beginner
Duration: 1:15:12
Speaker: : Abhi Pratap
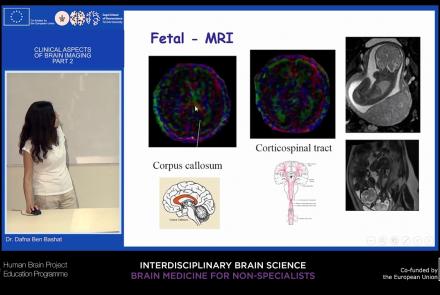
This lecture picks up from the previous lesson, providing an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 41:00
Speaker: : Dafna Ben Bashat

This lesson discusses both state-of-the-art detection and prevention schema in working with neurodegenerative diseases.
Difficulty level: Beginner
Duration: 1:02:29
Speaker: : Nir Giladi

This lesson provides a basic introduction to clinical presentation of schizophrenia, its etiology, and current treatment options.
Difficulty level: Beginner
Duration: 51:49
Speaker: : Wolfgang Fleischhacker

This lecture focuses on the rationale for employing neuroimaging methods for movement disorders.
Difficulty level: Beginner
Duration: 1:04:04
Speaker: : Bogdan Draganski

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture covers FAIR atlases, including their background and construction, as well as how they can be created in line with the FAIR principles.
Difficulty level: Beginner
Duration: 14:24
Speaker: : Heidi Kleven
Course:
This lecture covers the biomedical researcher's perspective on FAIR data sharing and the importance of finding better ways to manage large datasets.
Difficulty level: Beginner
Duration: 10:51
Speaker: : Adam Ferguson
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke

This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani
This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre

This lecture discusses the FAIR principles as they apply to electrophysiology data and metadata, the building blocks for community tools and standards, platforms and grassroots initiatives, and the challenges therein.
Difficulty level: Beginner
Duration: 8:11
Speaker: : Thomas Wachtler
This lecture contains an overview of electrophysiology data reuse within the EBRAINS ecosystem.
Difficulty level: Beginner
Duration: 15:57
Speaker: : Andrew Davison
This lecture contains an overview of the Distributed Archives for Neurophysiology Data Integration (DANDI) archive, its ties to FAIR and open-source, integrations with other programs, and upcoming features.
Difficulty level: Beginner
Duration: 13:34
Speaker: : Yaroslav O. Halchenko
This lecture contains an overview of the Australian Electrophysiology Data Analytics Platform (AEDAPT), how it works, how to scale it, and how it fits into the FAIR ecosystem.
Difficulty level: Beginner
Duration: 18:56
Speaker: : Tom Johnstone
This lecture discusses how to standardize electrophysiology data organization to move towards being more FAIR.
Difficulty level: Beginner
Duration: 15:51
Speaker: : Sylvain Takerkart

Course:
This lecture will provide an overview of Addgene, a tool that embraces the FAIR principles developed by members of the INCF Community. This will include an overview of Addgene, their mission, and available resources.
Difficulty level: Beginner
Duration: 12:05
Speaker: : Joanne Kamens