Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lecture discusses what defines an integrative approach regarding research and methods, including various study designs and models which are appropriate choices when attempting to bridge data domains; a necessity when whole-person modelling.
Difficulty level: Beginner
Duration: 1:28:14
Speaker: : Dan Felsky

This lecture covers a lot of post-war developments in the science of the mind, focusing first on the cognitive revolution, and concluding with living machines.
Difficulty level: Beginner
Duration: 2:24:35
Speaker: : Paul F.M.J. Verschure

This lecture provides an introduction to the principal of anatomical organization of neural systems in the human brain and spinal cord that mediate sensation, integrate signals, and motivate behavior.
Difficulty level: Beginner
Duration: 59:57
Speaker: : Lars Klimaschewski

This lecture focuses on the comprehension of nociception and pain sensation, highlighting how the somatosensory system and different molecular partners are involved in nociception.
Difficulty level: Beginner
Duration: 28:09
Speaker: : Serena Quarta
Course:
This lesson gives an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan
This lesson provides an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier
Course:
This lesson discusses FAIR principles and methods currently in development for assessing FAIRness.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier
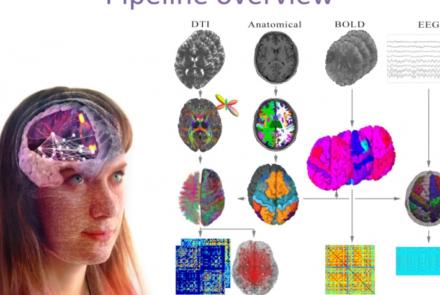
This presentation accompanies the paper entitled: An automated pipeline for constructing personalized virtual brains from multimodal neuroimaging data (see link below to download publication).
Difficulty level: Beginner
Duration: 4:56

This lesson provides an introduction to the lifecycle of EEG/ERP data, describing the various phases through which these data pass, from collection to publication.
Difficulty level: Beginner
Duration: 35:30
Speaker: : Kateřina Vařeková

In this lesson you will learn about experimental design for EEG acquisition, as well as the first phases of the EEG/ERP data lifecycle.
Difficulty level: Beginner
Duration: 30:04
Speaker: : Kateřina Vařeková

This lesson provides an overview of the current regulatory measures in place regarding experimental data security and privacy.
Difficulty level: Beginner
Duration: 31:00
Speaker: : Kateřina Vařeková

In this lesson, you will learn the appropriate methods for collection of both data and associated metadata during EEG experiments.
Difficulty level: Beginner
Duration: 29:14
Speaker: : Kateřina Vařeková

This lesson goes over methods for managing EEG/ERP data after it has been collected, from annotation to publication.
Difficulty level: Beginner
Duration: 39:25
Speaker: : Kateřina Vařeková

In this final lesson of the course, you will learn broadly about EEG signal processing, as well as specific applications which make this kind of brain signal valuable to researchers and clinicians.
Difficulty level: Beginner
Duration: 34:51
Speaker: : Kateřina Vařeková

This lecture on model types introduces the advantages of modeling, provide examples of different model types, and explain what modeling is all about.
Difficulty level: Beginner
Duration: 27:48
Speaker: : Gunnar Blohm

Course:
This lecture focuses on how to get from a scientific question to a model using concrete examples. We will present a 10-step practical guide on how to succeed in modeling. This lecture contains links to 2 tutorials, lecture/tutorial slides, suggested reading list, and 3 recorded Q&A sessions.
Difficulty level: Beginner
Duration: 29:52
Speaker: : Megan Peters

Course:
This lecture formalizes modeling as a decision process that is constrained by a precise problem statement and specific model goals. We provide real-life examples on how model building is usually less linear than presented in Modeling Practice I.
Difficulty level: Beginner
Duration: 22:51
Speaker: : Gunnar Blohm