Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26
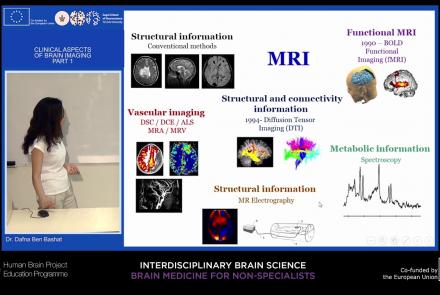
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lesson discusses both state-of-the-art detection and prevention schema in working with neurodegenerative diseases.
Difficulty level: Beginner
Duration: 1:02:29
Speaker: : Nir Giladi

In this lesson, you will learn about how genetics can contribute to our understanding of psychiatric phenotypes.
Difficulty level: Beginner
Duration: 55:15
Speaker: : Sven Cichon
Course:
This lesson discusses FAIR principles and methods currently in development for assessing FAIRness.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture covers the biomedical researcher's perspective on FAIR data sharing and the importance of finding better ways to manage large datasets.
Difficulty level: Beginner
Duration: 10:51
Speaker: : Adam Ferguson
Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke

This lecture covers the NIDM data format within BIDS to make your datasets more searchable, and how to optimize your dataset searches.
Difficulty level: Beginner
Duration: 12:33
Speaker: : David Keator
This lecture covers the processes, benefits, and challenges involved in designing, collecting, and sharing FAIR neuroscience datasets.
Difficulty level: Beginner
Duration: 11:35
Speaker: : Julie Boyle & Valentina Borghesani
This lecture covers positron emission tomography (PET) imaging and the Brain Imaging Data Structure (BIDS), and how they work together within the PET-BIDS standard to make neuroscience more open and FAIR.
Difficulty level: Beginner
Duration: 12:06
Speaker: : Melanie Ganz
This lecture covers the benefits and difficulties involved when re-using open datasets, and how metadata is important to the process.
Difficulty level: Beginner
Duration: 11:20
Speaker: : Elizabeth DuPre
This lecture provides guidance on the ethical considerations the clinical neuroimaging community faces when applying the FAIR principles to their research.
Difficulty level: Beginner
Duration: 13:11
Speaker: : Gustav Nilsonne

Course:
This lecture will provide an overview of Addgene, a tool that embraces the FAIR principles developed by members of the INCF Community. This will include an overview of Addgene, their mission, and available resources.
Difficulty level: Beginner
Duration: 12:05
Speaker: : Joanne Kamens

This lecture covers the IBI Data Standards and Sharing Working Group, including its history, aims, and projects.
Difficulty level: Beginner
Duration: 3:58
Speaker: : Kenji Doya
This session covers the framework of the International Brain Lab (IBL) and the data architecture used for this project.
Difficulty level: Beginner
Duration: 23:37
Speaker: : Kenneth Harris
The FOSTER portal has produced a number of guides to help implement Open Science practices in daily workflows, including The Open Science Training Handbook. It provides many basic definitions, concepts, and principles that are key components of open science, as well as general guidance for developing and implementing these practices in one's own research environments.
Difficulty level: Beginner
Duration:
Speaker: :