Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

Course:
This demonstration walks through how to import your data into MATLAB.
Difficulty level: Beginner
Duration: 6:10
Speaker: : MATLAB®

Course:
This lesson provides instruction regarding the various factors one must consider when preprocessing data, preparing it for statistical exploration and analyses.
Difficulty level: Beginner
Duration: 15:10
Speaker: : MATLAB®

Course:
This tutorial outlines, step by step, how to perform analysis by group and how to do change-point detection.
Difficulty level: Beginner
Duration: 2:49
Speaker: : MATLAB®

Course:
This tutorial walks through several common methods for visualizing your data in different ways depending on your data type.
Difficulty level: Beginner
Duration: 6:10
Speaker: : MATLAB®

Course:
This tutorial illustrates several ways to approach predictive modeling and machine learning with MATLAB.
Difficulty level: Beginner
Duration: 6:27
Speaker: : MATLAB®

Course:
This brief tutorial goes over how you can easily work with big data as you would with any size of data.
Difficulty level: Beginner
Duration: 3:55
Speaker: : MATLAB®

Course:
In this tutorial, you will learn how to deploy your models outside of your local MATLAB environment, enabling wider sharing and collaboration.
Difficulty level: Beginner
Duration: 3:52
Speaker: : MATLAB®

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This tutorial teaches users how to use Pandas objects to help store and manipulate various datasets in Python.
Difficulty level: Beginner
Duration: 1:21:40
Speaker: : Tal Yarkoni

Course:
This lesson gives a quick walkthrough the Tidyverse, an "opinionated" collection of R packages designed for data science, including the use of readr, dplyr, tidyr, and ggplot2.
Difficulty level: Beginner
Duration: 1:01:39
Speaker: : Thomas Mock

This lesson provides an overview of how to conceptualize, design, implement, and maintain neuroscientific pipelines in via the cloud-based computational reproducibility platform Code Ocean.
Difficulty level: Beginner
Duration: 17:01
Speaker: : David Feng

This lesson provides an overview of how to construct computational pipelines for neurophysiological data using DataJoint.
Difficulty level: Beginner
Duration: 17:37
Speaker: : Dimitri Yatsenko

This talk describes approaches to maintaining integrated workflows and data management schema, taking advantage of the many open source, collaborative platforms already existing.
Difficulty level: Beginner
Duration: 15:15
Speaker: : Erik C. Johnson

This hands-on tutorial walks you through DataJoint platform, highlighting features and schema which can be used to build robost neuroscientific pipelines.
Difficulty level: Beginner
Duration: 26:06
Speaker: : Milagros Marin

This lecture provides a detailed description of how to incorporate HED annotation into your neuroimaging data pipeline.
Difficulty level: Beginner
Duration: 33:36
Speaker: : Dung Truong
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

This lecture covers how to make modeling workflows FAIR by working through a practical example, dissecting the steps within the workflow, and detailing the tools and resources used at each step.
Difficulty level: Beginner
Duration: 15:14
Speaker: : Salvador Dura-Bernal

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman
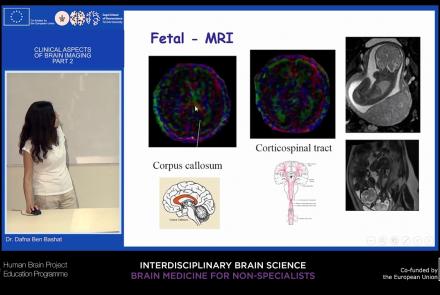
This lecture picks up from the previous lesson, providing an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 41:00
Speaker: : Dafna Ben Bashat