Lesson type
Difficulty level

Course:
This lesson describes the Neuroscience Gateway , which facilitates access and use of National Science Foundation High Performance Computing resources by neuroscientists.
Difficulty level: Beginner
Duration: 39:27
Speaker: : Subha Sivagnanam

Course:
This lesson gives an introduction to high-performance computing with the Compute Canada network, first providing an overview of use cases for HPC and then a hands-on tutorial. Though some examples might seem specific to the Calcul Québec, all computing clusters in the Compute Canada network share the same software modules and environments.
Difficulty level: Beginner
Duration: 02:49:34
Speaker: : Félix-Antoine Fortin

This talk highlights a set of platform technologies, software, and data collections that close and shorten the feedback cycle in research.
Difficulty level: Beginner
Duration: 57:52
Speaker: : Satrajit Ghosh

Course:
This lesson provides an overview of the database of Genotypes and Phenotypes (dbGaP), which was developed to archive and distribute the data and results from studies that have investigated the interaction of genotype and phenotype in humans.
Difficulty level: Beginner
Duration: 48:22
Speaker: : Michael Feolo

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

Course:
This demonstration walks through how to import your data into MATLAB.
Difficulty level: Beginner
Duration: 6:10
Speaker: : MATLAB®

Course:
This lesson provides instruction regarding the various factors one must consider when preprocessing data, preparing it for statistical exploration and analyses.
Difficulty level: Beginner
Duration: 15:10
Speaker: : MATLAB®

Course:
This tutorial outlines, step by step, how to perform analysis by group and how to do change-point detection.
Difficulty level: Beginner
Duration: 2:49
Speaker: : MATLAB®

Course:
This tutorial walks through several common methods for visualizing your data in different ways depending on your data type.
Difficulty level: Beginner
Duration: 6:10
Speaker: : MATLAB®

Course:
This tutorial illustrates several ways to approach predictive modeling and machine learning with MATLAB.
Difficulty level: Beginner
Duration: 6:27
Speaker: : MATLAB®

Course:
This brief tutorial goes over how you can easily work with big data as you would with any size of data.
Difficulty level: Beginner
Duration: 3:55
Speaker: : MATLAB®

Course:
In this tutorial, you will learn how to deploy your models outside of your local MATLAB environment, enabling wider sharing and collaboration.
Difficulty level: Beginner
Duration: 3:52
Speaker: : MATLAB®

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This tutorial teaches users how to use Pandas objects to help store and manipulate various datasets in Python.
Difficulty level: Beginner
Duration: 1:21:40
Speaker: : Tal Yarkoni

Course:
This lesson gives a quick walkthrough the Tidyverse, an "opinionated" collection of R packages designed for data science, including the use of readr, dplyr, tidyr, and ggplot2.
Difficulty level: Beginner
Duration: 1:01:39
Speaker: : Thomas Mock

Course:
In this lesson, while learning about the need for increased large-scale collaborative science that is transparent in nature, users also are given a tutorial on using Synapse for facilitating reusable and reproducible research.
Difficulty level: Beginner
Duration: 1:15:12
Speaker: : Abhi Pratap

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman
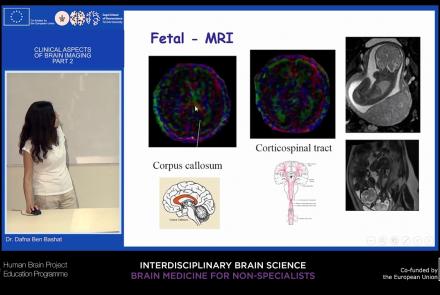
This lecture picks up from the previous lesson, providing an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 41:00
Speaker: : Dafna Ben Bashat

This lesson provides a basic introduction to clinical presentation of schizophrenia, its etiology, and current treatment options.
Difficulty level: Beginner
Duration: 51:49
Speaker: : Wolfgang Fleischhacker