Lesson type
Difficulty level

Course:
This hands-on tutorial explains how to run your own Minion session in the MetaCell cloud using jupityr notebooks.
Difficulty level: Beginner
Duration: 01:28:03
Speaker: : Daniel Aharoni, Phil Dong

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This hands-on tutorial walks you through DataJoint platform, highlighting features and schema which can be used to build robost neuroscientific pipelines.
Difficulty level: Beginner
Duration: 26:06
Speaker: : Milagros Marin

In this hands-on session, you will learn how to explore and work with DataLad datasets, containers, and structures using Jupyter notebooks.
Difficulty level: Beginner
Duration: 58:05
Speaker: : Michał Szczepanik

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This lesson gives a general introduction to the essentials of navigating through a Bash terminal environment. The lesson is based on the Software Carpentries "Introduction to the Shell" and was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 1:12:22
Speaker: : Ross Markello

Course:
This lesson covers Python applications to data analysis, demonstrating why it has become ubiquitous in data science and neuroscience. The lesson was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 2:38:45
Speaker: : Ross Markello

Course:
An introduction to data management, manipulation, visualization, and analysis for neuroscience. Students will learn scientific programming in Python, and use this to work with example data from areas such as cognitive-behavioral research, single-cell recording, EEG, and structural and functional MRI. Basic signal processing techniques including filtering are covered. The course includes a Jupyter Notebook and video tutorials.
Difficulty level: Beginner
Duration: 1:09:16
Speaker: : Aaron J. Newman

This lesson gives an in-depth introduction of ethics in the field of artificial intelligence, particularly in the context of its impact on humans and public interest. As the healthcare sector becomes increasingly affected by the implementation of ever stronger AI algorithms, this lecture covers key interests which must be protected going forward, including privacy, consent, human autonomy, inclusiveness, and equity.
Difficulty level: Beginner
Duration: 1:22:06
Speaker: : Daniel Buchman

This lesson describes a definitional framework for fairness and health equity in the age of the algorithm. While acknowledging the impressive capability of machine learning to positively affect health equity, this talk outlines potential (and actual) pitfalls which come with such powerful tools, ultimately making the case for collaborative, interdisciplinary, and transparent science as a way to operationalize fairness in health equity.
Difficulty level: Beginner
Duration: 1:06:35
Speaker: : Laura Sikstrom

Course:
In this lesson, while learning about the need for increased large-scale collaborative science that is transparent in nature, users also are given a tutorial on using Synapse for facilitating reusable and reproducible research.
Difficulty level: Beginner
Duration: 1:15:12
Speaker: : Abhi Pratap

This lecture covers a lot of post-war developments in the science of the mind, focusing first on the cognitive revolution, and concluding with living machines.
Difficulty level: Beginner
Duration: 2:24:35
Speaker: : Paul F.M.J. Verschure
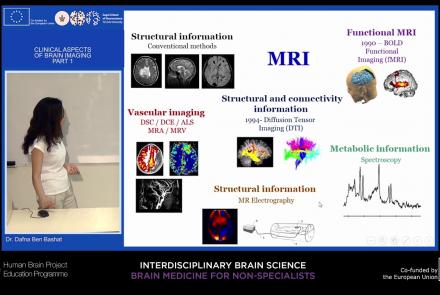
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lecture provides an overview of depression (epidemiology and course of the disorder), clinical presentation, somatic co-morbidity, and treatment options.
Difficulty level: Beginner
Duration: 37:51
Speaker: : Barbara Sperner-Unterweger

In this lesson, you will learn about how genetics can contribute to our understanding of psychiatric phenotypes.
Difficulty level: Beginner
Duration: 55:15
Speaker: : Sven Cichon

This lecture gives an introduction to the types of glial cells, homeostasis (influence of cerebral blood flow and influence on neurons), insulation and protection of axons (myelin sheath; nodes of Ranvier), microglia and reactions of the CNS to injury.
Difficulty level: Beginner
Duration: 40:32
Speaker: : Christine Bandtlow
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke