Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This hands-on tutorial walks you through DataJoint platform, highlighting features and schema which can be used to build robost neuroscientific pipelines.
Difficulty level: Beginner
Duration: 26:06
Speaker: : Milagros Marin

In this hands-on session, you will learn how to explore and work with DataLad datasets, containers, and structures using Jupyter notebooks.
Difficulty level: Beginner
Duration: 58:05
Speaker: : Michał Szczepanik

In this tutorial, you will learn how to use TVB-NEST toolbox on your local computer.
Difficulty level: Beginner
Duration: 2:16
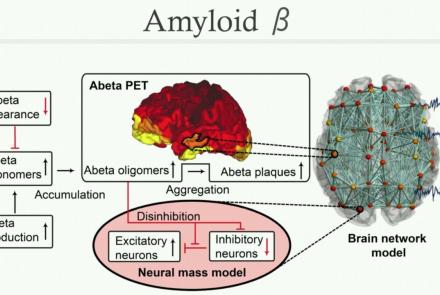
This tutorial provides instruction on how to perform multi-scale simulation of Alzheimer's disease on The Virtual Brain Simulation Platform.
Difficulty level: Beginner
Duration: 29:08

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This lesson gives a general introduction to the essentials of navigating through a Bash terminal environment. The lesson is based on the Software Carpentries "Introduction to the Shell" and was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 1:12:22
Speaker: : Ross Markello

Course:
This lesson covers Python applications to data analysis, demonstrating why it has become ubiquitous in data science and neuroscience. The lesson was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 2:38:45
Speaker: : Ross Markello

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

This lesson gives a description of the BrainHealth Databank, a repository of many types of health-related data, whose aim is to accelerate research, improve care, and to help better understand and diagnose mental illness, as well as develop new treatments and prevention strategies.
This lesson corresponds to slides 46-78 of the PDF below.
Difficulty level: Beginner
Duration: 1:12:25
Speaker: : Joanna Yu

This lecture covers the history of behaviorism and the ultimate challenge to behaviorism.
Difficulty level: Beginner
Duration: 1:19:08
Speaker: : Paul F.M.J. Verschure

This lecture covers various learning theories.
Difficulty level: Beginner
Duration: 1:00:42
Speaker: : Paul F.M.J. Verschure

This lecture covers a lot of post-war developments in the science of the mind, focusing first on the cognitive revolution, and concluding with living machines.
Difficulty level: Beginner
Duration: 2:24:35
Speaker: : Paul F.M.J. Verschure

In this lesson, you will learn about how genetics can contribute to our understanding of psychiatric phenotypes.
Difficulty level: Beginner
Duration: 55:15
Speaker: : Sven Cichon
Course:
This lesson gives an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan
This lesson provides an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan

In this lesson, you will hear about the current challenges regarding data management, as well as policies and resources aimed to address them.
Difficulty level: Beginner
Duration: 18:13
Speaker: : Mojib Javadi
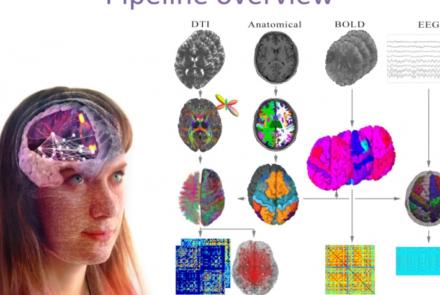
This presentation accompanies the paper entitled: An automated pipeline for constructing personalized virtual brains from multimodal neuroimaging data (see link below to download publication).
Difficulty level: Beginner
Duration: 4:56

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

This lecture on model types introduces the advantages of modeling, provide examples of different model types, and explain what modeling is all about.
Difficulty level: Beginner
Duration: 27:48
Speaker: : Gunnar Blohm