Lesson type
Difficulty level

Course:
This hands-on tutorial explains how to run your own Minion session in the MetaCell cloud using jupityr notebooks.
Difficulty level: Beginner
Duration: 01:28:03
Speaker: : Daniel Aharoni, Phil Dong

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This hands-on tutorial walks you through DataJoint platform, highlighting features and schema which can be used to build robost neuroscientific pipelines.
Difficulty level: Beginner
Duration: 26:06
Speaker: : Milagros Marin

In this hands-on session, you will learn how to explore and work with DataLad datasets, containers, and structures using Jupyter notebooks.
Difficulty level: Beginner
Duration: 58:05
Speaker: : Michał Szczepanik

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This lesson gives a general introduction to the essentials of navigating through a Bash terminal environment. The lesson is based on the Software Carpentries "Introduction to the Shell" and was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 1:12:22
Speaker: : Ross Markello

Course:
This lesson covers Python applications to data analysis, demonstrating why it has become ubiquitous in data science and neuroscience. The lesson was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 2:38:45
Speaker: : Ross Markello

Course:
An introduction to data management, manipulation, visualization, and analysis for neuroscience. Students will learn scientific programming in Python, and use this to work with example data from areas such as cognitive-behavioral research, single-cell recording, EEG, and structural and functional MRI. Basic signal processing techniques including filtering are covered. The course includes a Jupyter Notebook and video tutorials.
Difficulty level: Beginner
Duration: 1:09:16
Speaker: : Aaron J. Newman

Course:
The state of the field regarding the diagnosis and treatment of major depressive disorder (MDD) is discussed. Current challenges and opportunities facing the research and clinical communities are outlined, including appropriate quantitative and qualitative analyses of the heterogeneity of biological, social, and psychiatric factors which may contribute to MDD.
Difficulty level: Beginner
Duration: 1:29:28
Speaker: : Brett Jones, Victor Tang

This lesson contains both a lecture and a tutorial component. The lecture (0:00-20:03 of YouTube video) discusses both the need for intersectional approaches in healthcare as well as the impact of neglecting intersectionality in patient populations. The lecture is followed by a practical tutorial in both Python and R on how to assess intersectional bias in datasets. Links to relevant code and data are found below.
Difficulty level: Beginner
Duration: 52:26

Course:
This lesson delves into the opportunities and challenges of telepsychiatry. While novel digital approaches to clinical research and care have the potential to improve and accelerate patient outcomes, researchers and care providers must consider new population factors, such as digital disparity.
Difficulty level: Beginner
Duration: 1:20:28
Speaker: : Abhi Pratap

This lecture discusses what defines an integrative approach regarding research and methods, including various study designs and models which are appropriate choices when attempting to bridge data domains; a necessity when whole-person modelling.
Difficulty level: Beginner
Duration: 1:28:14
Speaker: : Dan Felsky
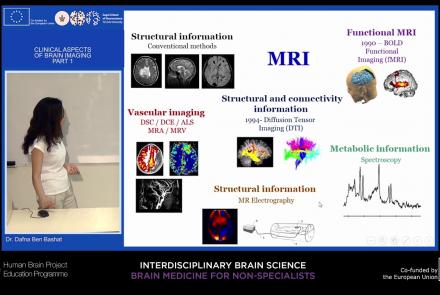
This lecture will provide an overview of neuroimaging techniques and their clinical applications.
Difficulty level: Beginner
Duration: 45:29
Speaker: : Dafna Ben Bashat

This lesson discusses both state-of-the-art detection and prevention schema in working with neurodegenerative diseases.
Difficulty level: Beginner
Duration: 1:02:29
Speaker: : Nir Giladi

This lesson provides a basic introduction to clinical presentation of schizophrenia, its etiology, and current treatment options.
Difficulty level: Beginner
Duration: 51:49
Speaker: : Wolfgang Fleischhacker
Course:
This lesson gives an introductory presentation on how data science can help with scientific reproducibility.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

Course:
The lecture provides an overview of the core skills and practical solutions required to practice reproducible research.
Difficulty level: Beginner
Duration: 1:25:17
Speaker: : Fernando Perez

Course:
This lecture covers the biomedical researcher's perspective on FAIR data sharing and the importance of finding better ways to manage large datasets.
Difficulty level: Beginner
Duration: 10:51
Speaker: : Adam Ferguson
Course:
This lecture covers the needs and challenges involved in creating a FAIR ecosystem for neuroimaging research.
Difficulty level: Beginner
Duration: 12:26
Speaker: : Camille Maumet
Course:
This lecture covers multiple aspects of FAIR neuroscience data: what makes it unique, the challenges to making it FAIR, the importance of overcoming these challenges, and how data governance comes into play.
Difficulty level: Beginner
Duration: 14:56
Speaker: : Damian Eke