Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

In this tutorial, you will learn how to use TVB-NEST toolbox on your local computer.
Difficulty level: Beginner
Duration: 2:16
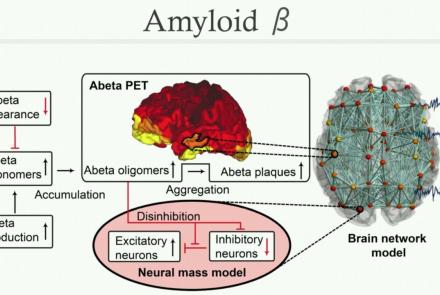
This tutorial provides instruction on how to perform multi-scale simulation of Alzheimer's disease on The Virtual Brain Simulation Platform.
Difficulty level: Beginner
Duration: 29:08

Course:
This lesson provides a brief overview of the Python programming language, with an emphasis on tools relevant to data scientists.
Difficulty level: Beginner
Duration: 1:16:36
Speaker: : Tal Yarkoni

Course:
This lesson gives a general introduction to the essentials of navigating through a Bash terminal environment. The lesson is based on the Software Carpentries "Introduction to the Shell" and was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 1:12:22
Speaker: : Ross Markello

Course:
This lesson covers Python applications to data analysis, demonstrating why it has become ubiquitous in data science and neuroscience. The lesson was given in the context of the BrainHack School 2020.
Difficulty level: Beginner
Duration: 2:38:45
Speaker: : Ross Markello

This lecture covers a lot of post-war developments in the science of the mind, focusing first on the cognitive revolution, and concluding with living machines.
Difficulty level: Beginner
Duration: 2:24:35
Speaker: : Paul F.M.J. Verschure

Introduction of the Foundations of Machine Learning in Python course - Day 01.
High-Performance Computing and Analytics Lab, University of Bonn
Difficulty level: Beginner
Duration: 35:24
Speaker: : Elena Trunz

This lesson discusses both state-of-the-art detection and prevention schema in working with neurodegenerative diseases.
Difficulty level: Beginner
Duration: 1:02:29
Speaker: : Nir Giladi
Course:
This lesson gives an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan
This lesson provides an introduction to simple spiking neuron models.
Difficulty level: Beginner
Duration: 48 Slides
Speaker: : Zubin Bhuyan
Course:
This lesson discusses FAIR principles and methods currently in development for assessing FAIRness.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier
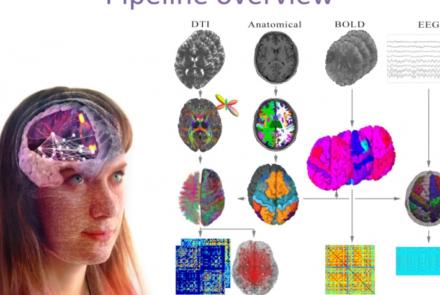
This presentation accompanies the paper entitled: An automated pipeline for constructing personalized virtual brains from multimodal neuroimaging data (see link below to download publication).
Difficulty level: Beginner
Duration: 4:56

This lecture on model types introduces the advantages of modeling, provide examples of different model types, and explain what modeling is all about.
Difficulty level: Beginner
Duration: 27:48
Speaker: : Gunnar Blohm

Course:
This lecture focuses on how to get from a scientific question to a model using concrete examples. We will present a 10-step practical guide on how to succeed in modeling. This lecture contains links to 2 tutorials, lecture/tutorial slides, suggested reading list, and 3 recorded Q&A sessions.
Difficulty level: Beginner
Duration: 29:52
Speaker: : Megan Peters

Course:
This lecture formalizes modeling as a decision process that is constrained by a precise problem statement and specific model goals. We provide real-life examples on how model building is usually less linear than presented in Modeling Practice I.
Difficulty level: Beginner
Duration: 22:51
Speaker: : Gunnar Blohm

Course:
This lecture focuses on the purpose of model fitting, approaches to model fitting, model fitting for linear models, and how to assess the quality and compare model fits. We will present a 10-step practical guide on how to succeed in modeling.
Difficulty level: Beginner
Duration: 26:46
Speaker: : Jan Drugowitsch

Course:
This lecture summarizes the concepts introduced in Model Fitting I and adds two additional concepts: 1) MLE is a frequentist way of looking at the data and the model, with its own limitations. 2) Side-by-side comparisons of bootstrapping and cross-validation.
Difficulty level: Beginner
Duration: 38.17
Speaker: : Kunlin Wei

This lecture provides an overview of the generalized linear models (GLM) course, originally a part of the Neuromatch Academy (NMA), an interactive online summer school held in 2020. NMA provided participants with experiences spanning from hands-on modeling experience to meta-science interpretation skills across just about everything that could reasonably be included in the label "computational neuroscience".
Difficulty level: Beginner
Duration: 33:58
Speaker: : Cristina Savin

This lecture further develops the concepts introduced in Machine Learning I. This lecture is part of the Neuromatch Academy (NMA), an interactive online computational neuroscience summer school held in 2020.
Difficulty level: Beginner
Duration: 29:30
Speaker: : I. Memming Park