Lesson type
Difficulty level

This lesson introduces several open science tools like Docker and Apptainer which can be used to develop portable and reproducible software environments.
Difficulty level: Beginner
Duration: 17:22
Speaker: : Joanes Grandjean

This lecture covers a wide range of aspects regarding neuroinformatics and data governance, describing both their historical developments and current trajectories. Particular tools, platforms, and standards to make your research more FAIR are also discussed.
Difficulty level: Beginner
Duration: 54:58
Speaker: : Franco Pestilli

Research Resource Identifiers (RRIDs) are ID numbers assigned to help researchers cite key resources (e.g., antibodies, model organisms, and software projects) in biomedical literature to improve the transparency of research methods.
Difficulty level: Beginner
Duration: 1:01:36
Speaker: : Maryann Martone

Course:
KnowledgeSpace is a community-based encyclopedia that links brain research concepts to data, models, and literature. It provides users with access to anatomy, gene expression, models, morphology, and physiology data from over 15 different neuroscience data/model repositories, such as Allen Institute for Brain Science and the Human Brain Project.
Difficulty level: Beginner
Duration: 0:58
Speaker: : Tom Gillespie

Course:
This talk deals with Identifiers.org, a central infrastructure for findable, accessible, interoperable and re-usable (FAIR) data, which provides a range of services to promote the citability of individual data providers and integration with e-infrastructures.
Difficulty level: Beginner
Duration: 36:41
Speaker: : Sarala Wimalaratne

This lecture covers how to make modeling workflows FAIR by working through a practical example, dissecting the steps within the workflow, and detailing the tools and resources used at each step.
Difficulty level: Beginner
Duration: 15:14
Speaker: : Salvador Dura-Bernal

Course:
This lecture will provide an overview of the INCF Training Suite, a collection of tools that embraces the FAIR principles developed by members of the INCF Community. This will include an overview of TrainingSpace, Neurostars, and KnowledgeSpace.
Difficulty level: Beginner
Duration: 09:50
Speaker: : Mathew Abrams

Course:
This session provides users with an introduction to tools and resources that facilitate the implementation of FAIR in their research.
Difficulty level: Beginner
Duration: 38:36

This video gives a short introduction to the EBRAINS data sharing platform, why it was developed, and how it contributes to open data sharing.
Difficulty level: Beginner
Duration: 17:32
Speaker: : Ida Aasebø

This video explains what metadata is, why it is important, and how you can organize your metadata to increase the FAIRness of your data on EBRAINS.
Difficulty level: Beginner
Duration: 17:23
Speaker: : Ulrike Schlegel

This video introduces the importance of writing a Data Descriptor to accompany your dataset on EBRAINS. It gives concrete examples on what information to include and highlights how this makes your data more FAIR.
Difficulty level: Beginner
Duration: 9:48
Speaker: : Ingrid Reiten

Course:
KnowledgeSpace (KS) is a data discoverability portal and neuroscience encyclopedia that was developed to make it easier for the neuroscience community to find publicly available datasets that adhere to the FAIR Principles and to provide an integrated view of neuroscience concepts found in Wikipedia and NeuroLex linked with PubMed and 17 of the world's leading neuroscience repositories. In short, KS provides a single point of entry where reseaerchers can search for a neuroscience concept of interest and receive results that include: i. a description of the term found in Wikipedia/NeuroLex, ii. links to publicly available datasets related to the concept of interest, and iii. up-to-date references that support the concept of interests found in PubMed. APIs are available so that developers of other neuroscience research infrastructures can integrate KS components in their infrastructures. If your repository or your favorite repository is not indexed in KS, please contact us.
Difficulty level: Beginner
Duration: 6:14
Speaker: : Heather Topple

In this lesson, users will learn about the importance of proper citation of software resources and tools used in neuroscientific research.
Difficulty level: Beginner
Duration: 58:00
Speaker: : Neil Chue Hong & Daniel Katz

Course:
This lesson describes the Neuroscience Gateway , which facilitates access and use of National Science Foundation High Performance Computing resources by neuroscientists.
Difficulty level: Beginner
Duration: 39:27
Speaker: : Subha Sivagnanam

Course:
This lesson gives an introduction to high-performance computing with the Compute Canada network, first providing an overview of use cases for HPC and then a hands-on tutorial. Though some examples might seem specific to the Calcul Québec, all computing clusters in the Compute Canada network share the same software modules and environments.
Difficulty level: Beginner
Duration: 02:49:34
Speaker: : Félix-Antoine Fortin

Course:
This talk presents an overview of CBRAIN, a web-based platform that allows neuroscientists to perform computationally intensive data analyses by connecting them to high-performance computing facilities across Canada and around the world.
Difficulty level: Beginner
Duration: 56:07
Speaker: : Shawn Brown

Course:
The Mouse Phenome Database (MPD) provides access to primary experimental trait data, genotypic variation, protocols and analysis tools for mouse genetic studies. Data are contributed by investigators worldwide and represent a broad scope of phenotyping endpoints and disease-related traits in naïve mice and those exposed to drugs, environmental agents or other treatments. MPD ensures rigorous curation of phenotype data and supporting documentation using relevant ontologies and controlled vocabularies. As a repository of curated and integrated data, MPD provides a means to access/re-use baseline data, as well as allows users to identify sensitized backgrounds for making new mouse models with genome editing technologies, analyze trait co-inheritance, benchmark assays in their own laboratories, and many other research applications. MPD’s primary source of funding is NIDA. For this reason, a majority of MPD data is neuro- and behavior-related.
Difficulty level: Beginner
Duration: 55:36
Speaker: : Elissa Chesler

Course:
This lesson introduces the EEGLAB toolbox, as well as motivations for its use.
Difficulty level: Beginner
Duration: 15:32
Speaker: : Arnaud Delorme
Course:
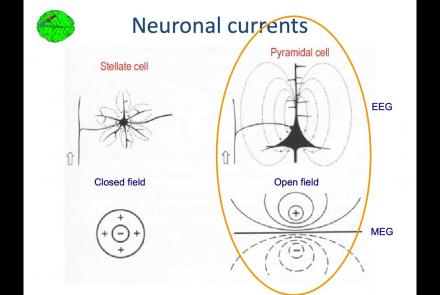
In this lesson, you will learn about the biological activity which generates and is measured by the EEG signal.
Difficulty level: Beginner
Duration: 6:53
Speaker: : Arnaud Delorme

Course:
This lesson goes over the characteristics of EEG signals when analyzed in source space (as opposed to sensor space).
Difficulty level: Beginner
Duration: 10:56
Speaker: : Arnaud Delorme