Lesson type
Difficulty level

This lesson continues with the second workshop on reproducible science, focusing on additional open source tools for researchers and data scientists, such as the R programming language for data science, as well as associated tools like RStudio and R Markdown. Additionally, users are introduced to Python and iPython notebooks, Google Colab, and are given hands-on tutorials on how to create a Binder environment, as well as various containers in Docker and Singularity.
Difficulty level: Beginner
Duration: 1:16:04
Speaker: : Erin Dickie and Sejal Patel

This is a tutorial introducing participants to the basics of RNA-sequencing data and how to analyze its features using Seurat.
Difficulty level: Intermediate
Duration: 1:19:17
Speaker: : Sonny Chen

This lecture goes into detailed description of how to process workflows in the virtual research environment (VRE), including approaches for standardization, metadata, containerization, and constructing and maintaining scientific pipelines.
Difficulty level: Intermediate
Duration: 1:03:55
Speaker: : Patrik Bey

This lesson provides an overview of how to conceptualize, design, implement, and maintain neuroscientific pipelines in via the cloud-based computational reproducibility platform Code Ocean.
Difficulty level: Beginner
Duration: 17:01
Speaker: : David Feng

In this workshop talk, you will receive a tour of the Code Ocean ScienceOps Platform, a centralized cloud workspace for all teams.
Difficulty level: Beginner
Duration: 10:24
Speaker: : Frank Zappulla

This lecture covers a wide range of aspects regarding neuroinformatics and data governance, describing both their historical developments and current trajectories. Particular tools, platforms, and standards to make your research more FAIR are also discussed.
Difficulty level: Beginner
Duration: 54:58
Speaker: : Franco Pestilli

Course:
JupyterHub is a simple, highly extensible, multi-user system for managing per-user Jupyter Notebook servers, designed for research groups or classes. This lecture covers deploying JupyterHub on a single server, as well as deploying with Docker using GitHub for authentication.
Difficulty level: Beginner
Duration: 1:36:27
Speaker: : Thomas Kluyver

Course:
This lesson introduces the EEGLAB toolbox, as well as motivations for its use.
Difficulty level: Beginner
Duration: 15:32
Speaker: : Arnaud Delorme
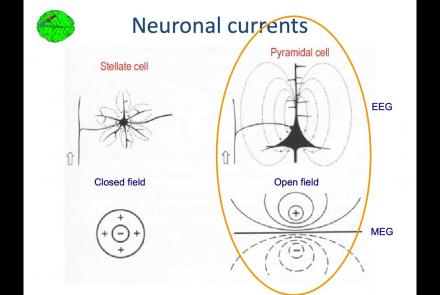
Course:
In this lesson, you will learn about the biological activity which generates and is measured by the EEG signal.
Difficulty level: Beginner
Duration: 6:53
Speaker: : Arnaud Delorme

Course:
This lesson goes over the characteristics of EEG signals when analyzed in source space (as opposed to sensor space).
Difficulty level: Beginner
Duration: 10:56
Speaker: : Arnaud Delorme

Course:
This lesson describes the development of EEGLAB as well as to what extent it is used by the research community.
Difficulty level: Beginner
Duration: 6:06
Speaker: : Arnaud Delorme

Course:
This lesson provides instruction as to how to build a processing pipeline in EEGLAB for a single participant.
Difficulty level: Beginner
Duration: 9:20
Speaker: :

Course:
Whereas the previous lesson of this course outlined how to build a processing pipeline for a single participant, this lesson discusses analysis pipelines for multiple participants simultaneously.
Difficulty level: Beginner
Duration: 10:55
Speaker: : Arnaud Delorme

Course:
In addition to outlining the motivations behind preprocessing EEG data in general, this lesson covers the first step in preprocessing data with EEGLAB, importing raw data.
Difficulty level: Beginner
Duration: 8:30
Speaker: : Arnaud Delorme

Course:
Continuing along the EEGLAB preprocessing pipeline, this tutorial walks users through how to import data events as well as EEG channel locations.
Difficulty level: Beginner
Duration: 11:53
Speaker: : Arnaud Delorme

Course:
This tutorial instructs users how to visually inspect partially pre-processed neuroimaging data in EEGLAB, specifically how to use the data browser to investigate specific channels, epochs, or events for removable artifacts, biological (e.g., eye blinks, muscle movements, heartbeat) or otherwise (e.g., corrupt channel, line noise).
Difficulty level: Beginner
Duration: 5:08
Speaker: : Arnaud Delorme

Course:
This tutorial provides instruction on how to use EEGLAB to further preprocess EEG datasets by identifying and discarding bad channels which, if left unaddressed, can corrupt and confound subsequent analysis steps.
Difficulty level: Beginner
Duration: 13:01
Speaker: : Arnaud Delorme

Course:
Users following this tutorial will learn how to identify and discard bad EEG data segments using the MATLAB toolbox EEGLAB.
Difficulty level: Beginner
Duration: 11:25
Speaker: : Arnaud Delorme

Course:
This demonstration walks through how to import your data into MATLAB.
Difficulty level: Beginner
Duration: 6:10
Speaker: : MATLAB®

Course:
This lesson provides instruction regarding the various factors one must consider when preprocessing data, preparing it for statistical exploration and analyses.
Difficulty level: Beginner
Duration: 15:10
Speaker: : MATLAB®