Lesson type
Difficulty level

Course:
This lecture presents an overview of functional brain parcellations, as well as a set of tutorials on bootstrap agregation of stable clusters (BASC) for fMRI brain parcellation.
Difficulty level: Advanced
Duration: 50:28
Speaker: : Pierre Bellec

This is the first of two workshops on reproducibility in science, during which participants are introduced to concepts of FAIR and open science. After discussing the definition of and need for FAIR science, participants are walked through tutorials on installing and using Github and Docker, the powerful, open-source tools for versioning and publishing code and software, respectively.
Difficulty level: Intermediate
Duration: 1:20:58
Speaker: : Erin Dickie and Sejal Patel

This is a hands-on tutorial on PLINK, the open source whole genome association analysis toolset. The aims of this tutorial are to teach users how to perform basic quality control on genetic datasets, as well as to identify and understand GWAS summary statistics.
Difficulty level: Intermediate
Duration: 1:27:18
Speaker: : Dan Felsky

This is a tutorial on using the open-source software PRSice to calculate a set of polygenic risk scores (PRS) for a study sample. Users will also learn how to read PRS into R, visualize distributions, and perform basic association analyses.
Difficulty level: Intermediate
Duration: 1:53:34
Speaker: : Dan Felsky

This lesson is an overview of transcriptomics, from fundamental concepts of the central dogma and RNA sequencing at the single-cell level, to how genetic expression underlies diversity in cell phenotypes.
Difficulty level: Intermediate
Duration: 1:29:08
Speaker: : Shreejoy Tripathy

Course:
This lesson describes the principles underlying functional magnetic resonance imaging (fMRI), diffusion-weighted imaging (DWI), tractography, and parcellation. These tools and concepts are explained in a broader context of neural connectivity and mental health.
Difficulty level: Intermediate
Duration: 1:47:22
Speaker: : Erin Dickie and John Griffiths

Course:
This tutorial introduces pipelines and methods to compute brain connectomes from fMRI data. With corresponding code and repositories, participants can follow along and learn how to programmatically preprocess, curate, and analyze functional and structural brain data to produce connectivity matrices.
Difficulty level: Intermediate
Duration: 1:39:04
Speaker: : Erin Dickie and John Griffiths

This lesson is the first of three hands-on tutorials as part of the workshop Research Workflows for Collaborative Neuroscience. This tutorial goes over how to visualize data with Scanpy, a scalable toolkit for analyzing single-cell gene expression.
Difficulty level: Intermediate
Duration: 25:26
Speaker: : David Feng & Frank Zappulla

In this third and final hands-on tutorial from the Research Workflows for Collaborative Neuroscience workshop, you will learn about workflow orchestration using open source tools like DataJoint and Flyte.
Difficulty level: Intermediate
Duration: 22:36
Speaker: : Daniel Xenes

This lecture describes how to build research workflows, including a demonstrate using DataJoint Elements to build data pipelines.
Difficulty level: Intermediate
Duration: 47:00
Speaker: : Dimitri Yatsenko

Course:
This video will document the process of creating a pipeline rule for batch processing on brainlife.
Difficulty level: Intermediate
Duration: 0:57
Speaker: :

This lesson introduces the practical exercises which accompany the previous lessons on animal and human connectomes in the brain and nervous system.
Difficulty level: Intermediate
Duration: 4:10
Speaker: : Dan Goodman

This tutorial provides instruction on how to simulate brain tumors with TVB (reproducing publication: Marinazzo et al. 2020 Neuroimage). This tutorial comprises a didactic video, jupyter notebooks, and full data set for the construction of virtual brains from patients and health controls.
Difficulty level: Intermediate
Duration: 10:01

The tutorial on modelling strokes in TVB includes a didactic video and jupyter notebooks (reproducing publication: Falcon et al. 2016 eNeuro).
Difficulty level: Intermediate
Duration: 7:43

This lecture provides an introduction to the Brain Imaging Data Structure (BIDS), a standard for organizing human neuroimaging datasets.
Difficulty level: Intermediate
Duration: 56:49
Speaker: : Chris Gorgolewski

This tutorial covers the fundamentals of collaborating with Git and GitHub.
Difficulty level: Intermediate
Duration: 2:15:50
Speaker: : Elizabeth DuPre

Course:
This lecture and tutorial focuses on measuring human functional brain networks, as well as how to account for inherent variability within those networks.
Difficulty level: Intermediate
Duration: 50:44
Speaker: : Caterina Gratton

Course:
This lesson provides an overview of Jupyter notebooks, Jupyter lab, and Binder, as well as their applications within the field of neuroimaging, particularly when it comes to the writing phase of your research.
Difficulty level: Intermediate
Duration: 50:28
Speaker: : Elizabeth DuPre
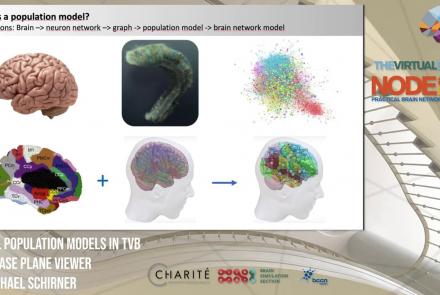
This lesson introduces population models and the phase plane, and is part of the The Virtual Brain (TVB) Node 10 Series, a 4-day workshop dedicated to learning about the full brain simulation platform TVB, as well as brain imaging, brain simulation, personalised brain models, and TVB use cases.
Difficulty level: Intermediate
Duration: 1:10:41
Speaker: : Michael Schirner

In this tutorial, you will learn how to run a typical TVB simulation.
Difficulty level: Intermediate
Duration: 1:29:13
Speaker: : Paul Triebkorn