Lesson type
Difficulty level
Course:
This lesson discusses FAIR principles and methods currently in development for assessing FAIRness.
Difficulty level: Beginner
Duration:
Speaker: : Michel Dumontier

This lecture provides an overview of successful open-access projects aimed at describing complex neuroscientific models, and makes a case for expanded use of resources in support of reproducibility and validation of models against experimental data.
Difficulty level: Beginner
Duration: 1:00:39
Speaker: : Sharon Crook

This lecture provides an introduction to the Brain Imaging Data Structure (BIDS), a standard for organizing human neuroimaging datasets.
Difficulty level: Intermediate
Duration: 56:49
Speaker: : Chris Gorgolewski

This lesson provides an overview of Neurodata Without Borders (NWB), an ecosystem for neurophysiology data standardization. The lecture also introduces some NWB-enabled tools.
Difficulty level: Beginner
Duration: 29:53
Speaker: : Oliver Ruebel
Course:
This lesson outlines Neurodata Without Borders (NWB), a data standard for neurophysiology which provides neuroscientists with a common standard to share, archive, use, and build analysis tools for neurophysiology data.
Difficulty level: Intermediate
Duration: 29:53
Speaker: : Oliver Ruebel

Course:
This lecture covers the rationale for developing the DAQCORD, a framework for the design, documentation, and reporting of data curation methods in order to advance the scientific rigour, reproducibility, and analysis of data.
Difficulty level: Intermediate
Duration: 17:08
Speaker: : Ari Ercole

Course:
This tutorial demonstrates how to use PyNN, a simulator-independent language for building neuronal network models, in conjunction with the neuromorphic hardware system SpiNNaker.
Difficulty level: Intermediate
Duration: 25:49
Speaker: : Christian Brenninkmeijer

This lecture covers a wide range of aspects regarding neuroinformatics and data governance, describing both their historical developments and current trajectories. Particular tools, platforms, and standards to make your research more FAIR are also discussed.
Difficulty level: Beginner
Duration: 54:58
Speaker: : Franco Pestilli

Course:
This lecture introduces you to the basics of the Amazon Web Services public cloud. It covers the fundamentals of cloud computing and goes through both the motivations and processes involved in moving your research computing to the cloud.
Difficulty level: Intermediate
Duration: 3:09:12
Speaker: : Amanda Tan & Ariel Rokem

This lecture discusses how FAIR practices affect personalized data models, including workflows, challenges, and how to improve these practices.
Difficulty level: Beginner
Duration: 13:16
Speaker: : Kelly Shen

In this talk, you will learn how brainlife.io works, and how it can be applied to neuroscience data.
Difficulty level: Beginner
Duration: 10:14
Speaker: : Franco Pestilli

Course:
As a part of NeuroHackademy 2020, this lecture delves into cloud computing, focusing on Amazon Web Services.
Difficulty level: Beginner
Duration: 01:43:59
Speaker: : Tara Madhyastha, Andrew Crabb, Ariel Rokem

Course:
This talk presents an overview of CBRAIN, a web-based platform that allows neuroscientists to perform computationally intensive data analyses by connecting them to high-performance computing facilities across Canada and around the world.
Difficulty level: Beginner
Duration: 56:07
Speaker: : Shawn Brown

This lesson gives a description of the BrainHealth Databank, a repository of many types of health-related data, whose aim is to accelerate research, improve care, and to help better understand and diagnose mental illness, as well as develop new treatments and prevention strategies.
This lesson corresponds to slides 46-78 of the PDF below.
Difficulty level: Beginner
Duration: 1:12:25
Speaker: : Joanna Yu

This tutorial provides instruction on how to simulate brain tumors with TVB (reproducing publication: Marinazzo et al. 2020 Neuroimage). This tutorial comprises a didactic video, jupyter notebooks, and full data set for the construction of virtual brains from patients and health controls.
Difficulty level: Intermediate
Duration: 10:01
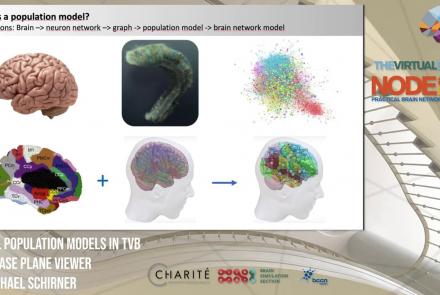
This lesson introduces population models and the phase plane, and is part of the The Virtual Brain (TVB) Node 10 Series, a 4-day workshop dedicated to learning about the full brain simulation platform TVB, as well as brain imaging, brain simulation, personalised brain models, and TVB use cases.
Difficulty level: Intermediate
Duration: 1:10:41
Speaker: : Michael Schirner

This lesson introduces TVB-multi-scale extensions and other TVB tools which facilitate modeling and analyses of multi-scale data.
Difficulty level: Intermediate
Duration: 36:10
Speaker: : Dionysios Perdikis
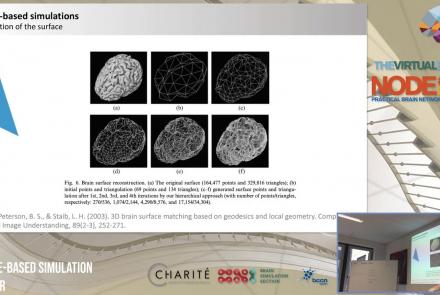
This lecture delves into cortical (i.e., surface-based) brain simulations, as well as subcortical (i.e., deep brain) stimulations, covering the definitions, motivations, and implementations of both.
Difficulty level: Intermediate
Duration: 39:05
Speaker: : Jil Meier

This lecture provides an introduction to entropy in general, and multi-scale entropy (MSE) in particular, highlighting the potential clinical applications of the latter.
Difficulty level: Intermediate
Duration: 39:05
Speaker: : Jil Meier

This lecture gives an overview of how to prepare and preprocess neuroimaging (EEG/MEG) data for use in TVB.
Difficulty level: Intermediate
Duration: 1:40:52
Speaker: : Paul Triebkorn